
Automating Semrush reports export with Python without going through the API
Requirements
- Python
- Pip
- Requirements.txt
- Chrome Driver for Selenium
- A Semrush account
- The script available on Github : https://github.com/cestmoihugo/semrush_reports
Python
Last version available on : https://www.python.org/downloads/
Pip
Pip will allow you to easily install packages for Python. Normaly it is already installed with Python’s last version but you should still check if it’s the case. To do so, open your terminal and type :
pip --version
If there is no error, we’re good. Otherwise you call install pip here.
Requirements.txt
To make the script work, enter the command line below in your terminal. This will install all the needed packages.
pip install -r requirements.txt
Selenium & Chrome Driver
Selenium is a web browser library (Chrome, Firefox, etc..) used to carry out automating tests. For this script we will use Chrome and we will need to download its driver. To do do :
1) Go on chrome://settings/help and check your version
2) Go on http://chromedriver.chromium.org/downloads and download the corresponding version
3) Move the file chromedriver into the folder driver
How the script works
Script setup
Open semrush_report.py with any text editor and put your Semrush login / password within these 2 lines.
# Input your SemRush Login here semrush_mail ="XXXXXXXXX" semrush_password ="XXXXXXXXXX"
Running the script
Open a terminal and type:
cd /chemindudossier/semrush_reports-master python semrush_report.py
The first line allows us to move into the folder where is located semrush_report.py and the second one launches the script. On Mac, you’ll need to type python3 instead of python.
Features
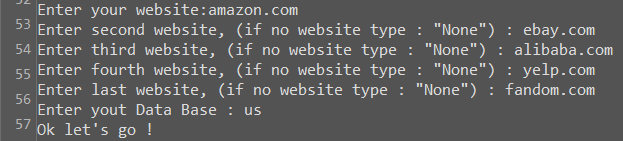
Websites input : you can input up to 5 different websites. If you wanna get less reports, you just need to type none and you’ll jump directly to the database input.
Database input : now that you’ve entered your websites, you need to choose a database among the ones given. Those databases are the 28 countries available on Semrush on which we’ll get the keywords and rankings.
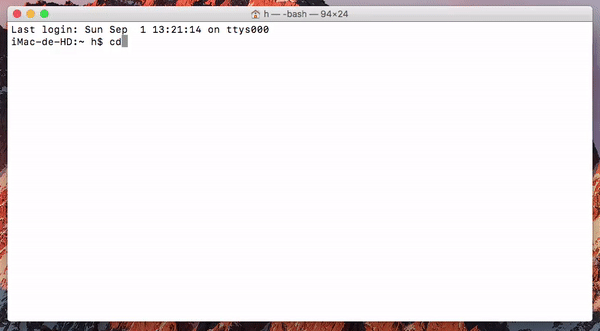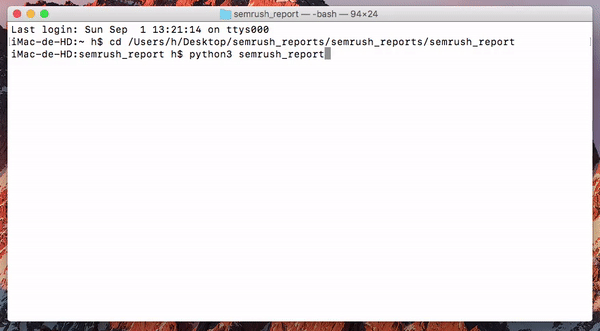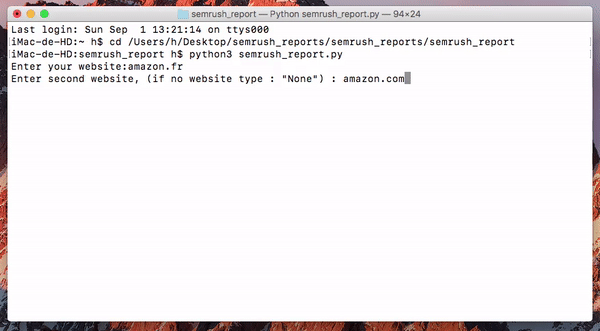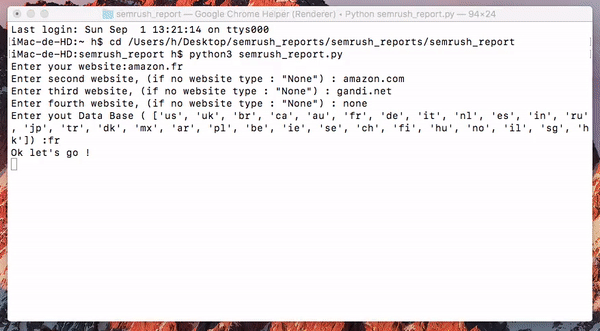
The inputs below will get the organics reports for the 3 websites on the French database.
Enter your website: amazon.fr Enter second website, (if no website type : "None") : alibaba.com Enter third website, (if no website type : "None") : aliexpress.com Enter fourth website, (if no website type : "None") : none Enter yout Data Base ( ['us', 'uk', 'br', 'ca', 'au', 'fr', 'de', 'it', 'nl', 'es', 'in', 'ru', 'jp', 'tr', 'dk', 'mx', 'ar', 'pl', 'be', 'ie', 'se', 'ch', 'fi', 'hu', 'no', 'il', 'sg', 'hk']) :fr Ok let's go !
Now that the script is running just wait a little bit si it gets all the reports. It also informs you when a report has been downloaded.

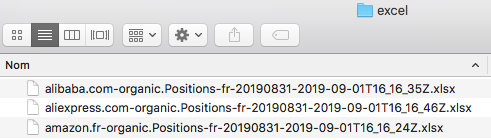
Getting the reports
The downloaded reports are in the folder /excel/ in /semrush_reports/
Handling Errors
Website synthax : to validate a website input, it must have a correct synthax, otherwise the script detects it and ask you to enter a website again.
![]()
Report with no result : if a website does not have any result in Semrush, the script will let you know and will continue downloading the rest of the reports.

Possible Improvements
Report level : root domain / subdomain / subfolder / exact URL. Currently the reports are basd on the root domain but it would be possible to add a new variable in order to choose the level. However, this would ask the user to input 1 additionnal information by website which means more actions required for him.
Wrapping it up
Why this script ?
simply to automate the organic reports export and be able to do other stuff on the side.
Why not go through the API ?
not everyone has a Semrush account with API access. Moreover, each API call costs money, here we just automate the login and the export.
Nothing else ?
nope.